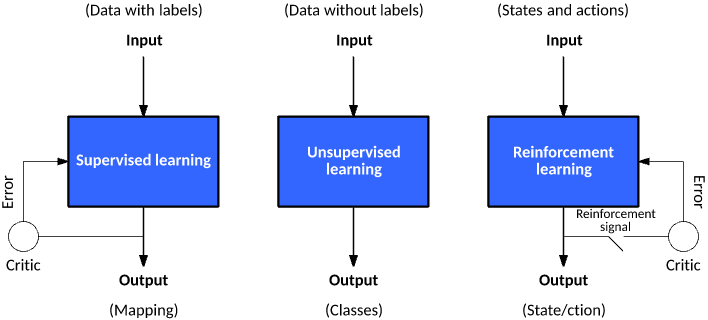
Supervised learning,Unsupervised learning and Reinforcement learning in Machinelearning
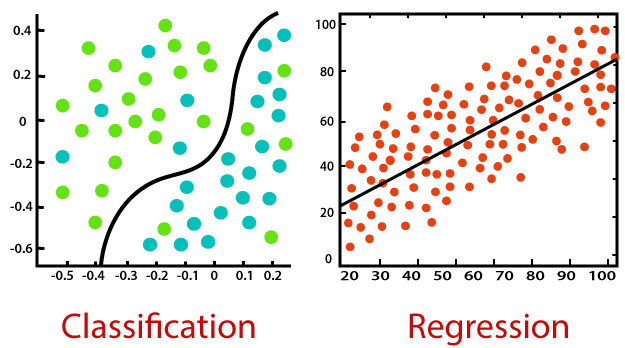
- Classification: Divide instance data into appropriate categories.
- Application example: Determine whether the website is hacked (two classifications), automatic recognition of handwritten digits (multi-classification)
- Regression: mainly used to predict numerical data.
- Application examples: forecasting of stock price fluctuations, housing price forecasts, etc.
Supervised learning:
- The value of the target variable must be determined so that the machine learning algorithm can discover the relationship between the feature and the target variable. In supervised learning, given a set of data, we know what the correct output should look like and know that there is a specific relationship between input and output. (including: classification and regression)
- Sample set: training data + test data
- Training sample = feature + target variable (label: classification – discrete value / regression – continuous value)
- The features are usually the columns of the training sample set, which are measured independently.
- Target Variable: The target variable is the test result of the machine learning prediction algorithm.
- In the classification algorithm, the types of target variables are usually nominal (such as true and false), while in regression algorithms they are usually continuous (eg, 1~100).
- Supervised learning needs to pay attention to the problem:
- Offset variance tradeoff
- Functional complexity and quantity of training data
- The dimension of the input space
- Output value in noise
- Knowledge representation:
- Can be in the form of a rule set [for example: math scores greater than 90 is excellent]
- Can be in the form of probability distribution [for example: through statistical distribution, 90% of students’ mathematics scores, below 70 points, then greater than 70 points is considered excellent]
- You can use an instance of the training sample set [for example: through the sample set, we train a model instance to get young, high in mathematics, elegant in conversation, we think it is excellent]
Unsupervised learning:
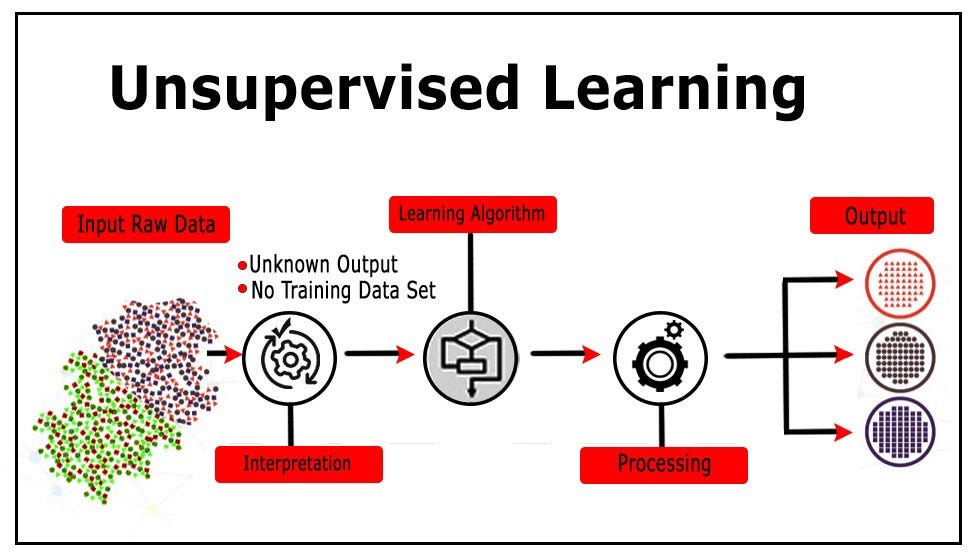
- In machine learning, the problem with unsupervised learning is to try to find hidden structures in unlabeled data. Because the examples provided to learners are unmarked, there are no errors or reward signals to evaluate potential solutions.
- Unsupervised learning is a closely related issue of statistical data density estimates. However, unsupervised learning also includes techniques for seeking, summarizing, and interpreting the main features of the data. Many of the methods used in unsupervised learning are based on data mining methods for processing data.
- The data has no category information and does not give a target value.
- Types covered by unsupervised learning:
- Clustering: In unsupervised learning, the process of dividing a data set into multiple classes of similar objects is called clustering.
- Density estimation: Estimate the similarity to the grouping by the tightness of the sample distribution.
- In addition, unsupervised learning can also reduce the dimensions of data features so that we can display data information more intuitively using 2D or 3D graphics.
Reinforcement learning:
This algorithm can train the program to make a decision. The program tries all possible actions in a given situation, recording the results of the different actions and trying to find the best one to make the decision. There is a Markov decision process for this type of algorithm.
Next:Dataset Division,Model fit,Model Indicators, Feature Engineering in Machine Learning


0 Comments