Robust speech Recognition And Translation From A Noisy Input
Speech recognition is the inter-disciplinary sub-field of computational linguistics that develops methodologies and technologies that enables the recognition and translation of spoken language into text by computers.

Speech translation is the process by which spoken words are
translated and spoken allowed in a different language.It enables speakers of different languages to communicate.
PRE-PROCESSING:-We are training the system by recording a given word multiple times in different dialects,so that the computer(system) can identify the word given by user in a clear way.
NOISE CANCELLATION:-We are taking a noisy input signal from the speaker.We are doing FFT and we are shifting the obtained signal to origin .We pass the above signal through a butterworth filter and we cancel the low pitchand high pitch noises and we obtain the speech signal with less noise.

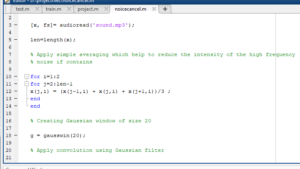 We get the noise cancelled speech signal as input signal and compare with already existing signals in the dataset by getting the correlation coefficients.
We get the noise cancelled speech signal as input signal and compare with already existing signals in the dataset by getting the correlation coefficients.
We store the correlation coefficients in an array and we obtain the signal which has maximum correlation coefficient.
We get the text mapped to that signal in this stage and further we proceed for translation.
Correlation coefficient =xcorr(a,b)
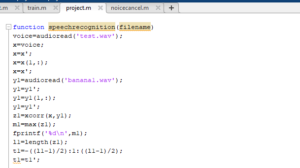
a=voice signal ,b=individual samples present in the dataset.
First we will read audio files and store their corresponding correlation constant in an array.
Then we will get file with maximum correlation constant.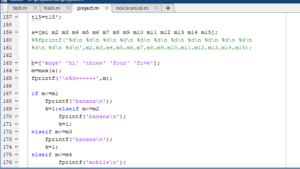
we will map our translated files with file we got which is having maximum correlation constant with test file
we obtain the text related to the speech.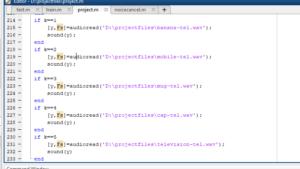
We map the text to the corresponding voice file of the word present in the dataset in different languages.
Hence,we obtain the translation
For full code and project files visit my github account and don’t forget to give a star.

0 Comments