Various types of GANs ,Evaluation Metrics of GANs
Issues in Training:
Generator Diminished Gradient: Discriminator gets too successful that the generator gradient vanishes and learns nothing.
As seen earlier the training of a GAN is typically alternating between Gradient Ascent on Discriminator and Gradient Descent on Generator. But optimizing GD on generator doesn’t work well.
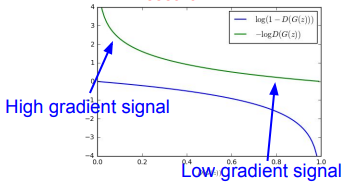
Consider the above graph, the term in GD of Generator is represented in blue. When the value of log(1-D(G(z)) is nearing one it means the generator is tending to be successful in fooling the discriminator (since D(G(z)) is nearing 1). But when the value of log(1-D(G(z)) is near 0, we expect of generator to learn better as its performance is poor. Here, we can observe that the signal is a low gradient one and to make the generator learn from a low gradient signal is difficult task.
To make things easy for the Generator i.e., to make it learn from a high gradient signal when D(G(z)) is 0, we flip the or simply use Gradient ascent.
Here Instead of minimizing likelihood of discriminator being correct, now maximize likelihood of discriminator being wrong. Same objective of fooling discriminator, but now higher gradient signal for bad samples => works much better! Standard in practice.
Mode Collapse:
Generator has reached a stage where it is able to fool the discriminator very easily. It starts producing a single variety of a particular sample (which has been able to fool the discriminator successfully) thereby decreasing the variety and spread of data. The generator collapses and starts producing a limited variety of samples.
Types of GANs:
DC-GAN (Deep Convolutional GAN) :
The images produced by vanilla GAN are noisy and incomprehensible.
Replacing the Multi-Layer Perceptron (Generator and Discriminator) with Deep Convolutional Networks yields this variant of GAN called DC-GAN.
⦁ Architecture guidelines for stable DCGANs:
⦁ Replace all max pooling with convolutional stride
⦁ Use transposed convolution for upsampling.
⦁ Eliminate fully connected layers. (FC layers kill the locality)
⦁ Use Batch normalization except the output layer for the generator and the input layer of the discriminator. (stabilizes data, Mode collapse reduced)
⦁ Use ReLU in the generator except for the output which uses tanh.
⦁ Use LeakyReLU in the discriminator.
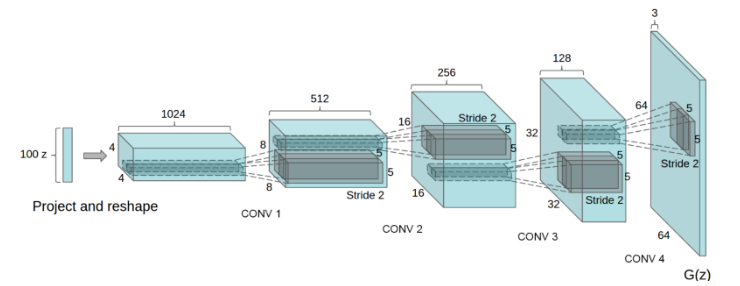
DC GAN generator used for LSUN scene modeling. A 100-dimensional uniform distribution Z is projected to a small spatial extent convolutional representation with many feature maps. A series of four fractionally-strided convolutions (in some recent papers, these are wrongly called deconvolutions) then convert this high-level representation into a 64 × 64 pixel image. Notably, no fully connected or pooling layers are used.
DCGAN is used for Image Generation and Data Augmentation.
CGAN (Conditional GAN):
Both the Generator and the Discriminator are conditioned with some extra information say y, which can be class labels. Labels act as an extension to the latent space z to generate and discriminate images better. The Loss function uses Conditional Probability.
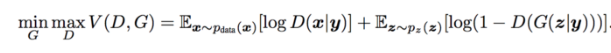
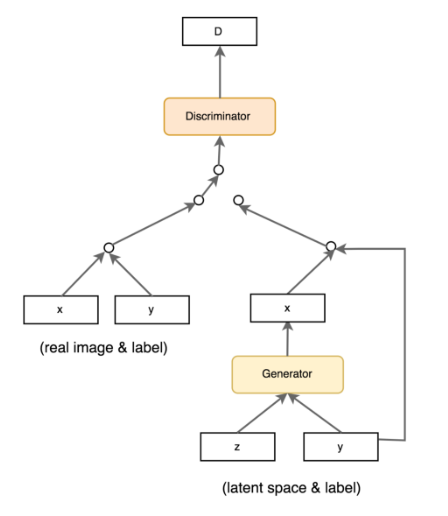
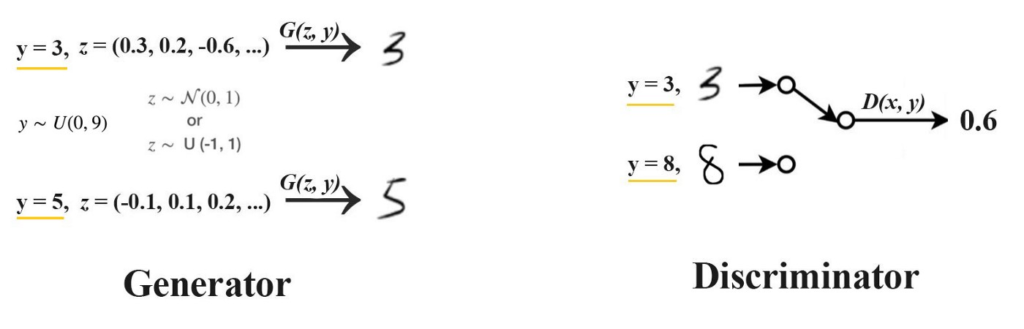
In the above fig. along with the latent space z, the generator is fed with the class label. The Generator generated the digits as shown in the figure. Same is the case with the discriminator. The Discriminator is fed with the digits along with label information, y.
InfoGAN:
In case of CGAN the label is provided from the dataset. Alternatively, we can use our discriminator to extract all these latent features.
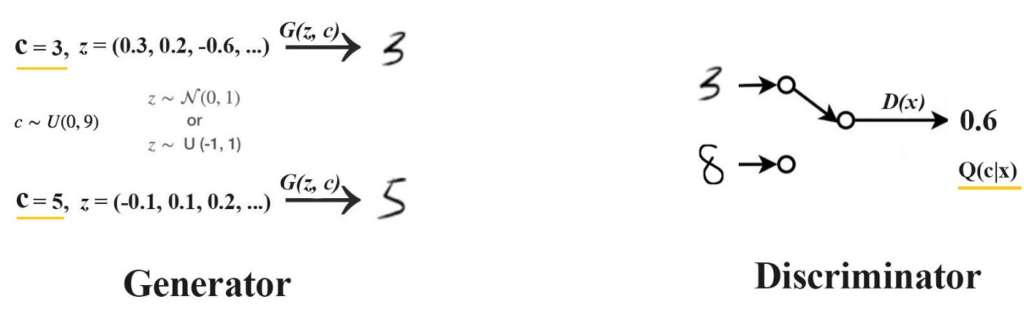

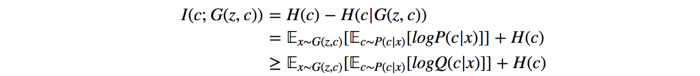
We subtract the regular GAN cost function with an extra term I(x; y) to form our new cost function.
I (mutual information) measures how much we know x if we know y. I(c;x)equals to 0 if the image x and the estimated c is completely irrelevant. Otherwise, if the discriminator can correctly predict c, I will be high and reduce the InfoGAN cost. Without proof, the mutual information I can be estimated using entropy. We use Q(c|x) and P(C) to establish a lower bound for I.
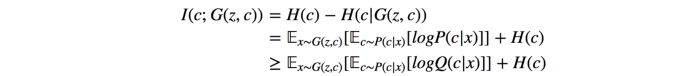
where H stands for entropy. When the model performs, I will converge to its lower bound. The concept of mutual information may take time to settle in. Here is a snippet of code for calculating Mutual Information.

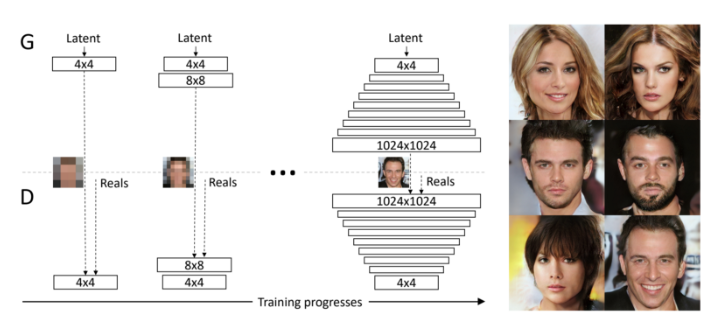
Progressive GAN:
Progressive Gan is the progressive growing of GAN. The GAN is trained multiple times. It is mainly used for high resolution image generation.
In phase 1, it takes in a latent feature z and uses two convolution layers to generate 4×4 images. Then, we train the discriminator with the generated images and the 4×4 real images. Once the training stables, we add 2 more convolution layers to upsampling the image to 8×8 and 2 more convolution layers to down sampling images in the discriminator.
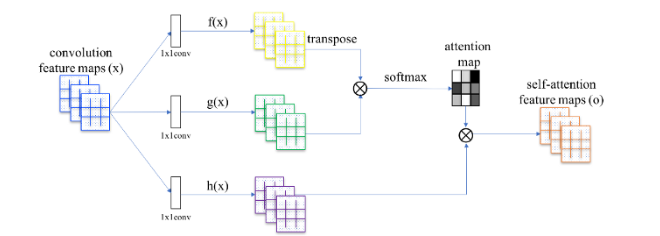
SAGAN (Self-Attention GAN):
While convolutional filters are good at exploring spatial locality information, the receptive fields may not be large enough to cover larger structures. We can increase the filter size or the depth of the deep network but this will make GANs even harder to train.
Alternatively, we can apply the attention concept. For example, to refine the image quality of the eye region (the red dot on the left figure), SAGAN only uses the feature map region on the highlight area in the middle figure. As shown below, this region has a larger receptive field and the context is more focus and more relevant. The right figure shows another example on the mouth area (the green dot).

In SAGAN, we locate the attention area to improve the rendering of a specific area. Self-attention layer is added to both generator and discriminator. The figure below shows how attention maps are generated and used.
Evaluation Metrics:
⦁ Inception Score (IS):
IS uses two criteria in measuring the performance of GAN:
⦁ The quality of the generated images, and
⦁ their diversity.
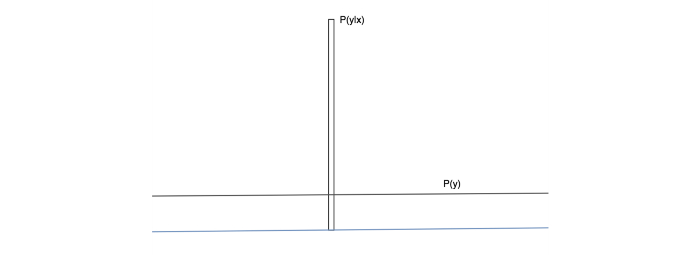
Entropy can be viewed as randomness. If the value of a random variable x is highly predictable, it has low entropy. On the contrary, if it is highly unpredictable, the entropy is high. For example, in the figure below, we have two probability distributions p(x). p2 has a higher entropy than p1because p2 has a more uniform distribution and therefore, less predictable about what x is.

In GAN, we want the conditional probability P(y|x) to be highly predictable (low entropy). i.e. given an image, we should know the object type easily. So we use an Inception network to classify the generated images and predict P(y|x) — where y is the label and x is the generated data. This reflects the quality of the images. Next we need to measure the diversity of images.
P(y) is the marginal probability computed as:
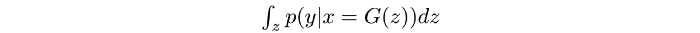
If the generated images are diverse, the data distribution for y should be uniform (high entropy).
The figure below visualizes this concept.
To combine these two criteria, we compute their KL-divergence and use the equation below to compute IS.
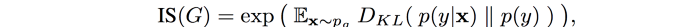
One shortcoming for IS is that it can misrepresent the performance if it only generates one image per class. p(y) will still be uniform even though the diversity is low.
⦁ Fréchet Inception Distance (FID)
In FID, we use the Inception network to extract features from an intermediate layer. Then we model the data distribution for these features using a multivariate Gaussian distribution with mean µ and covariance Σ. The FID between the real images x and generated images g is computed as:
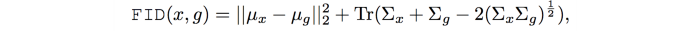
where Tr sums up all the diagonal elements.
Lower FID values mean better image quality and diversity.
⦁ Precision, Recall, F1 Score:
⦁ Generated Images similar to real images – High Precision
⦁ Generator can generate any sample in training data – High Recall
⦁ Harmonic avg. of Precision, Recall – F1 Score

0 Comments