DeepFace vs Facenet for face recognition
Introduction:
Face Recognition problems can be broadly classified into two categories
⦁ Face Verification: Identifying if the given face is of the claimed person
⦁ Face Recognition: Identifying different instances (of faces) of the claimed person
Other type of problems includes Clustering (grouping similar faces together)
Simple Techniques for face verification are pixel by pixel matching wherein you match each corresponding pixel.
One-shot learning is an object categorization problem in computer vision. Whereas most machine learning based object categorization algorithms require training on hundreds or thousands of images and very large datasets, one-shot learning aims to learn information about object categories from one, or only a few, training images.
FaceNet is one of the recent breakthroughs for Face recognition tasks which uses One Shot Learning flow.
Check our article for more methods on Face recognition.
Facenet:
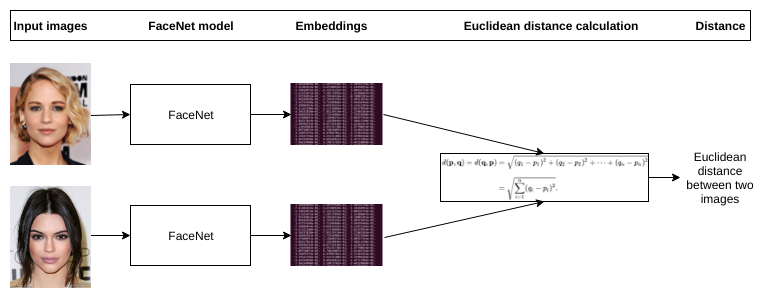
FaceNet is a Deep Neural Network used for face verification, recognition and clustering. It directly learns mappings from face images to a compact Euclidean plane. When an input image of 96*96 RGB is given it simply outputs a 128-dimensional vector which is the embedding of the image.
This conversion into a simple Euclidean plane simplifies all the tasks as it is simple distance calculation.
Verification – Thresholding the distance between two given embeddings
Recognition – k-NN classification problem
Clustering – K-means clustering of the embeddings.
Triplet Loss:
Triplet loss is used to learn the embeddings. The name is derived from its use of three images to learn the mapping namely anchor, positive and negative.
The loss function is such that it minimizes the distance between the anchor and positive and simultaneously moves the anchor and negative further away.
The Loss L is
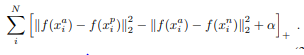
Where a is the anchor, p is positive and n is negative and α is the margin enforced between positive and negative samples.
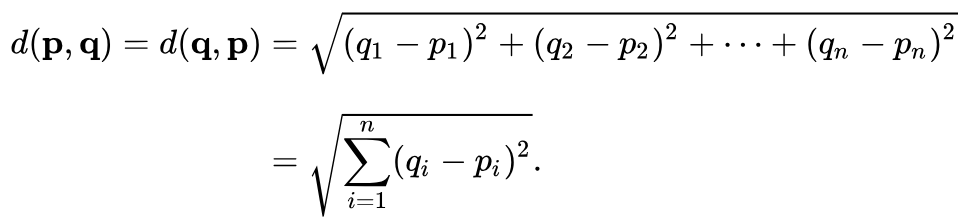
The Distance is computes based on the above formula where q, p represent the obtained embeddings.
Architecture:
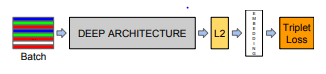
The paper describes that network consists of a batch input layer and a deep CNN followed by L2 normalization, which results in the face embedding. This is followed by the triplet loss during training. The figure represents the basic model of the FaceNet. Squared L2 is used to directly correspond to embedding vectors. These embeddings are fine tuned by minimizing the triplet loss.
The most important process is the selection of triplet. The triplets should be chosen in such a way that given an anchor image xia , select the “hardest” positive image (of the same person) as xip (i.e. the one that’s furthest away in the dataset) and select the “hardest” negative image (of a different person) as xin (i.e. the one that’s closest in the dataset). If this triplet doesn’t violate condition, then none with that anchor will.
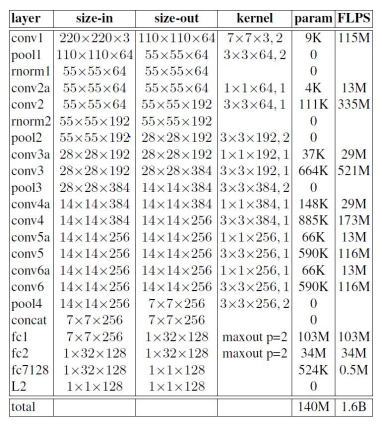
There are two types of Deep architectures used i.e., the Zeiler&Fergus inspired architecture and the inception inspired architecture. Their practical differences lie in the difference of parameters and FLOPS. The best model may be different depending on the application.
Zeilur and Fergus Inspired Architecture:
Inception-Inspired Architecture:
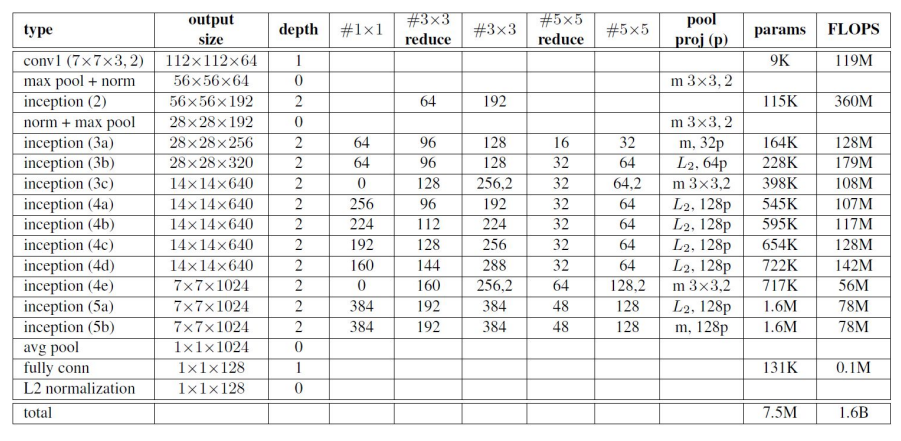
The DNN used are trained using Stochastic Gradient Descent (SGD), backpropagation and AdaGrad optimizer. The initial learning rate is 0.05 and the margin is 0.2.
Once the FaceNet model is trained, we can create the embedding for the face by feeding into the model. In order to compare two images, create the embedding for both images by feeding through the model separately. Then we can use above formula to find the distance which will be lower value for similar faces and higher value for different face.
On the LFW dataset, the accuracy was 99.63% and on the YTF dataset the accuracy was 95.12%.
DeepFace:
DeepFace is a deep neural network used for the purpose of face recognition. It follows the flow of detect, align, represent and classify to achieve the task. It consists of 3D Face Modelling, followed by piecewise affine transformation. Later, a face representation is derived from a 9-layer Deep neural Network. The 2D images are warped into 3D plane with the help of 67 anchor points.
It doesn’t matter if the face is tilted, at an angle, or in bad lighting. DeepFace is unlike previous generations of facial recognition software which follow the conventions steps: detect → align → represent → classify. Facebook’s DeepFace employs 3D face modeling and derives a picture from a deep network of millions of parameters. DeepFace uses an algorithm that is capable of identifying a face with a 97.25% accuracy. The average human can do so with a 97.5% accuracy.
Architecture:

The figure illustrates a front-end of a single convolution-pooling-convolution filtering on the rectified input, followed by three locally-connected layers and two fully-connected layers. Colours illustrate feature maps produces at each layer. The net includes more than 120 million parameters, where more than 95% come from the local and fully connected layers.
The probability of each class is maximized by minimizing the cross-entropy loss. The output is a 4096-dimensional vector of labels.
The network is trained on SFC Dataset using Stochastic Gradient descent (SGD) with momentum set to 0.9. Initial learning rate is 0.01 which decreases to 0.001 as the training progresses. The model is trained for 15 epochs on the dataset with a mini batch size of 128.
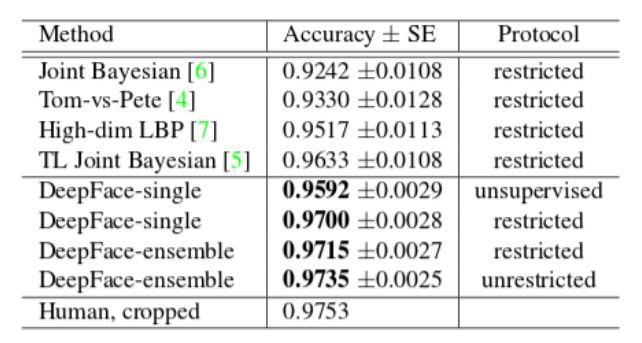
When tested on the LFW dataset the accuracy is about 97.25% and 91.4% on the YTF Dataset. The above table shows the performance of various state of the art methods on the LFW Dataset.
Advantages and Disadvantages:
⦁ FaceNet:
Pros – Very large comprehensive dataset is used (260 Million)
Cons – The model is too deep. Even though the dataset is comprehensive it is too big in size and is difficult to handle. To overcome this generally this model is not trained from scratch and the pre-trained model is used.
⦁ DeepFace:
Pros – At the time of publication, it was best (2014)
Cons – Requires Large Dataset, 3D modelling is complicated. Better methods like Face++, FaceNet were proposed.
Applications:
⦁ FaceNet : The Implementations of MTCNN and Openface are based on FaceNet. The broader applications include (but not limited to) Face recognition
⦁ DeepFace : Face Detection, Face Analysis and attributes, Emotion analysis and Facial Expression, Verification
check our article on k-means clustering here.

3 Comments
Virgil Shern · December 26, 2021 at 8:11 am
I could not resist commenting. Exceptionally well written!
Will Brassil · December 30, 2021 at 2:25 am
I simply needed to appreciate you yet again. I am not sure the things I would’ve achieved in the absence of the type of pointers discussed by you over such a field. It was before the intimidating case in my circumstances, however , taking note of a well-written tactic you managed the issue made me to weep over contentment. I’m thankful for the assistance and believe you are aware of a powerful job you have been carrying out training men and women by way of your blog post. I am sure you haven’t come across all of us.
Face Recognition and Neural Style Transfer in Deep Learning - projectsflix · July 20, 2019 at 11:32 am
[…] our article on DeepFace and Facenet for face recognition for more details about face […]